Note: 10x Genomics does not provide support for community-developed tools and makes no guarantees regarding their function or performance. Please contact tool developers with any questions. If you have feedback about Analysis Guides, please email analysis-guides@10xgenomics.com.
The field of spatial transcriptomics aims to capture a tissue's complete transcriptomic profile and map gene expression to specific locations, shedding light on the spatial distribution of diverse cell types and their molecular activities. 10x’s Visium assays capture and localize transcript expression using barcode patterned slides. In the Visium HD Spatial Gene Expression assay, the barcodes are patterned in a continuous grid of 2x2 µm squares. By default, the Space Ranger v3 pipeline creates 8x8 µm and 16x16 µm bins of gene expression data with the option to create custom sized square bins (Figure 1). Each bin contains the gene-wise summation of the UMI counts of a number of 2x2 µm squares. For example, 8x8 µm binned data is the gene-wise sum of the UMI counts from a box that is 4 squares wide by 4 squares tall (Figure 1). This is not the only approach for binning gene expression data. An alternative approach is to use the information contained within a microscope image of the tissue used in the Visium HD assay to create custom bins. This Analysis Guide demonstrates this approach. Herein, we use the nuclei staining from a high-resolution H&E image to partition barcodes into bins based on the nuclei they correspond to (Figure 1). The partitioning of barcodes into nuclei-specific bins, mimics single cell like data since the gene counts will now be reported on a per-cell basis.

- High-resolution H&E image of the sample used in the Visium HD Gene Expression assay
- Output from a completed Space Ranger count analysis
- Familiarity with Python programming
The image taken by the CytAssist is not suitable for this analysis, becuase it is only a cytoplasmic eosin stain and lacks the hematoxylin stain for cell nuclei.
To generate custom nuclei-specific bins, we begin by segmenting a high-resolution H&E image to create a nuclei mask. Then we use the shape and location of each nucleus in the mask to sort barcodes into bins that correspond to each individual nucleus. Lastly, we perform gene-wise summation of UMI counts in each bin, resulting in a gene-by-binned barcode matrix.
This Analysis Guide employs StarDist for nucleus segmentation of mouse intestinal cells. A custom python script is then used to bin and sum the gene expression data based on the segmented nuclei mask. The resulting gene-by-binned barcode matrix is well-suited for visualization and downstream analyses such as clustering. All steps are conducted using the Python programming language. Although not explicitly discussed in this guide, this approach can be extended to other programming or scripting languages, including R.
You can download the data for this Analysis Guide from our public datasets. The mouse small intestine data is available here.
For this tutorial you will need the following files.
- 2x2 µm filtered barcode matrix (filtered_feature_bc_matrix.h5)
- This file is located in the
/outs/binned_outputs/square_002umdirectory of a completed Space Ranger run. - The filtered_feature_bc_matrix.h5 is an HDF5 formatted file where the number of UMIs associated with a feature or gene is stored in the rows of a matrix and each column of the matrix is a barcode.
- This file is located in the
- Parquet tissue position matrix (tissue_positions.parquet)
- This files is located in the
/outs/binned_outputs/square_002um/spatialdirectory of a completed Space Ranger run. - The tissue_positions.parquet file contains a table of the location of each 2x2 µm barcode square where each column is a barcode.
- This files is located in the
- High-resolution mouse intestine image (Visium_HD_Mouse_Small_Intestine_tissue_image.btf)
- This is an image generated by the user using a microscope.
- The name and location of this file is user defined.
- The time to transfer a high-resolution image can vary depending on internet access, and it may take a significant amount of time due to the file's size.
The filtered_feature_bc_matrix.h5 and tissue_positions.parquet files are packaged together in our public dataset in the 2x2 µm square outputs. The high-resolution H&E microscope image of the mouse intestine is avaible at this link. If you are running the analysis on a server, you can use the command line below to download the two files. Once the files are downloaded, copy them into the same directory.
curl -O https://cf.10xgenomics.com/samples/spatial-exp/3.0.0/Visium_HD_Mouse_Small_Intestine/Visium_HD_Mouse_Small_Intestine_binned_outputs.tar.gz
curl -O https://cf.10xgenomics.com/samples/spatial-exp/3.0.0/Visium_HD_Mouse_Small_Intestine/Visium_HD_Mouse_Small_Intestine_tissue_image.btf
Miniconda We recommend using Miniconda to install the Python libraries used in this Analysis guide. Please follow the Miniconda install directions at this link.
Important Python Libraries
stardistis a deep-learning library for star-convex object detection of cells/nuclei.geopandasis an extension of the pandas library for working with geospatial data.squidpyis a collection of tools that are built onscanpyandanndatafor the visualization and analysis of spatial gene expression data. It is used in this guide mainly for thescanpyandanndatalibraries.fastparquetis a Python library for efficient reading and writing of Apache Parquet files.
Execute the following commands to install these Python libraries.
# Update conda
conda update conda
# Create the conda environment, add the conda-forge channel, and set channel priority.
conda create -n stardist-env
# Activate the environment
conda activate stardist-env
conda config --env --add channels conda-forge
conda config --env --set channel_priority strict
# Install Python libraries
conda install -c conda-forge stardist
conda install python=3 geopandas
conda install -c conda-forge squidpy
conda install -c conda-forge fastparquet
If there is difficulty installing StarDist using Miniconda, there are instructions on installing StarDist using pip on its GitHub repository.
All of the following code blocks are suitable for copying and pasting into a Jupyter notebook or into one Python script.
The following code block imports the required Python Libraries and configures the image plotting of the Juypter notebook. Comment out the lines beginning with "%" if copying and pasting into one Python script.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import anndata
import geopandas as gpd
import scanpy as sc
from tifffile import imread, imwrite
from csbdeep.utils import normalize
from stardist.models import StarDist2D
from shapely.geometry import Polygon, Point
from scipy import sparse
from matplotlib.colors import ListedColormap
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
We define functions to help with plotting results in the next code block.
# General image plotting functions
def plot_mask_and_save_image(title, gdf, img, cmap, output_name=None, bbox=None):
if bbox is not None:
# Crop the image to the bounding box
cropped_img = img[bbox[1]:bbox[3], bbox[0]:bbox[2]]
else:
cropped_img = img
# Plot options
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# Plot the cropped image
axes[0].imshow(cropped_img, cmap='gray', origin='lower')
axes[0].set_title(title)
axes[0].axis('off')
# Create filtering polygon
if bbox is not None:
bbox_polygon = Polygon([(bbox[0], bbox[1]), (bbox[2], bbox[1]), (bbox[2], bbox[3]), (bbox[0], bbox[3])])
# Filter for polygons in the box
intersects_bbox = gdf['geometry'].intersects(bbox_polygon)
filtered_gdf = gdf[intersects_bbox]
else:
filtered_gdf=gdf
# Plot the filtered polygons on the second axis
filtered_gdf.plot(cmap=cmap, ax=axes[1])
axes[1].axis('off')
axes[1].legend(loc='upper left', bbox_to_anchor=(1.05, 1))
# Save the plot if output_name is provided
if output_name is not None:
plt.savefig(output_name, bbox_inches='tight') # Use bbox_inches='tight' to include the legend
else:
plt.show()
def plot_gene_and_save_image(title, gdf, gene, img, adata, bbox=None, output_name=None):
if bbox is not None:
# Crop the image to the bounding box
cropped_img = img[bbox[1]:bbox[3], bbox[0]:bbox[2]]
else:
cropped_img = img
# Plot options
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
# Plot the cropped image
axes[0].imshow(cropped_img, cmap='gray', origin='lower')
axes[0].set_title(title)
axes[0].axis('off')
# Create filtering polygon
if bbox is not None:
bbox_polygon = Polygon([(bbox[0], bbox[1]), (bbox[2], bbox[1]), (bbox[2], bbox[3]), (bbox[0], bbox[3])])
# Find a gene of interest and merge with the geodataframe
gene_expression = adata[:, gene].to_df()
gene_expression['id'] = gene_expression.index
merged_gdf = gdf.merge(gene_expression, left_on='id', right_on='id')
if bbox is not None:
# Filter for polygons in the box
intersects_bbox = merged_gdf['geometry'].intersects(bbox_polygon)
filtered_gdf = merged_gdf[intersects_bbox]
else:
filtered_gdf = merged_gdf
# Plot the filtered polygons on the second axis
filtered_gdf.plot(column=gene, cmap='inferno', legend=True, ax=axes[1])
axes[1].set_title(gene)
axes[1].axis('off')
axes[1].legend(loc='upper left', bbox_to_anchor=(1.05, 1))
# Save the plot if output_name is provided
if output_name is not None:
plt.savefig(output_name, bbox_inches='tight') # Use bbox_inches='tight' to include the legend
else:
plt.show()
def plot_clusters_and_save_image(title, gdf, img, adata, bbox=None, color_by_obs=None, output_name=None, color_list=None):
color_list=["#7f0000","#808000","#483d8b","#008000","#bc8f8f","#008b8b","#4682b4","#000080","#d2691e","#9acd32","#8fbc8f","#800080","#b03060","#ff4500","#ffa500","#ffff00","#00ff00","#8a2be2","#00ff7f","#dc143c","#00ffff","#0000ff","#ff00ff","#1e90ff","#f0e68c","#90ee90","#add8e6","#ff1493","#7b68ee","#ee82ee"]
if bbox is not None:
cropped_img = img[bbox[1]:bbox[3], bbox[0]:bbox[2]]
else:
cropped_img = img
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
axes[0].imshow(cropped_img, cmap='gray', origin='lower')
axes[0].set_title(title)
axes[0].axis('off')
if bbox is not None:
bbox_polygon = Polygon([(bbox[0], bbox[1]), (bbox[2], bbox[1]), (bbox[2], bbox[3]), (bbox[0], bbox[3])])
unique_values = adata.obs[color_by_obs].astype('category').cat.categories
num_categories = len(unique_values)
if color_list is not None and len(color_list) >= num_categories:
custom_cmap = ListedColormap(color_list[:num_categories], name='custom_cmap')
else:
# Use default tab20 colors if color_list is insufficient
tab20_colors = plt.cm.tab20.colors[:num_categories]
custom_cmap = ListedColormap(tab20_colors, name='custom_tab20_cmap')
merged_gdf = gdf.merge(adata.obs[color_by_obs].astype('category'), left_on='id', right_index=True)
if bbox is not None:
intersects_bbox = merged_gdf['geometry'].intersects(bbox_polygon)
filtered_gdf = merged_gdf[intersects_bbox]
else:
filtered_gdf = merged_gdf
# Plot the filtered polygons on the second axis
plot = filtered_gdf.plot(column=color_by_obs, cmap=custom_cmap, ax=axes[1], legend=True)
axes[1].set_title(color_by_obs)
legend = axes[1].get_legend()
legend.set_bbox_to_anchor((1.05, 1))
axes[1].axis('off')
# Move legend outside the plot
plot.get_legend().set_bbox_to_anchor((1.25, 1))
if output_name is not None:
plt.savefig(output_name, bbox_inches='tight')
else:
plt.show()
# Plotting function for nuclei area distribution
def plot_nuclei_area(gdf,area_cut_off):
fig, axs = plt.subplots(1, 2, figsize=(15, 4))
# Plot the histograms
axs[0].hist(gdf['area'], bins=50, edgecolor='black')
axs[0].set_title('Nuclei Area')
axs[1].hist(gdf[gdf['area'] < area_cut_off]['area'], bins=50, edgecolor='black')
axs[1].set_title('Nuclei Area Filtered:'+str(area_cut_off))
plt.tight_layout()
plt.show()
# Total UMI distribution plotting function
def total_umi(adata_, cut_off):
fig, axs = plt.subplots(1, 2, figsize=(12, 4))
# Box plot
axs[0].boxplot(adata_.obs["total_counts"], vert=False, widths=0.7, patch_artist=True, boxprops=dict(facecolor='skyblue'))
axs[0].set_title('Total Counts')
# Box plot after filtering
axs[1].boxplot(adata_.obs["total_counts"][adata_.obs["total_counts"] > cut_off], vert=False, widths=0.7, patch_artist=True, boxprops=dict(facecolor='skyblue'))
axs[1].set_title('Total Counts > ' + str(cut_off))
# Remove y-axis ticks and labels
for ax in axs:
ax.get_yaxis().set_visible(False)
plt.tight_layout()
plt.show()
In the following code block, change the file path to the location of the high-resolution image. After importing the image, it is percentile normalized. Adjust the min and max percentile parameters as needed for other images by assessing the image mask for accuracy. Percentile normalization scales pixel values by the specified min and max percentiles.
# Load the image file
# Change dir_base as needed to the directory where the downloaded example data is stored
dir_base = '/path_to_data/'
filename = 'SJ0309_MsSI_slide08_01_20x_BF_01.btf'
img = imread(dir_base + filename)
# Load the pretrained model
model = StarDist2D.from_pretrained('2D_versatile_he')
# Percentile normalization of the image
# Adjust min_percentile and max_percentile as needed
min_percentile = 5
max_percentile = 95
img = normalize(img, min_percentile, max_percentile)
Execute the code block below to create the nucleus segmentation mask. This step has a long runtime and it will vary significantly depending on the chosen parameter settings. The nms threshold (nms_thresh) is set to a small number to reduce the probability of nuclei overlap. The nms_thresh parameter may require adjustment for different images. Also, it may be necessary to adjust the probability threshold (prob_thresh) for different images. Larger prob_thresh values will result in fewer segmented objects. The optimal values for prob_thresh and nm_thresh will depend on visual assessment of the nucleus segmentation mask.
# Predict cell nuclei using the normalized image
# Adjust nms_thresh and prob_thresh as needed
labels, polys = model.predict_instances_big(img, axes='YXC', block_size=4096, prob_thresh=0.01,nms_thresh=0.001, min_overlap=128, context=128, normalizer=None, n_tiles=(4,4,1))
The function predict_instances_big divides the input image into blocks, processes them individually using predict_instances, and then combines the results.
In the next code block, we convert the results from StarDist into a Geodataframe. We will use the Geodataframe for barcode binning.
# Creating a list to store Polygon geometries
geometries = []
# Iterating through each nuclei in the 'polys' DataFrame
for nuclei in range(len(polys['coord'])):
# Extracting coordinates for the current nuclei and converting them to (y, x) format
coords = [(y, x) for x, y in zip(polys['coord'][nuclei][0], polys['coord'][nuclei][1])]
# Creating a Polygon geometry from the coordinates
geometries.append(Polygon(coords))
# Creating a GeoDataFrame using the Polygon geometries
gdf = gpd.GeoDataFrame(geometry=geometries)
gdf['id'] = [f"ID_{i+1}" for i, _ in enumerate(gdf.index)]
To visualize the segmentation results, we will choose a region of interest from the high-resolution H&E image and define a bounding box. The bounding box delineates the boundaries of the region of interest. Selecting a smaller region of the image allows us to zoom in and inspect the segmentation of nuclei more carefully. In this demo we focus on one region, however, multiple regions should be inspected to determine if the normalization parameters and the model prediction parameters need further refinement.
Defining a bounding box involves specifying the coordinates for each corner. The ROI manager in Fiji is a convenient tool that can determine these coordinates (Figure 2). To get started, open the high-resolution image in Fiji. Next, use the rectangular selection tool to choose a region of interest (ROI). Once the ROI is created, follow these steps:
- Navigate to the menu bar and select "Analyze" > "Tools" > "ROI Manager" > "Add [t]". Alternatively, use the shortcut Ctrl + T (Windows/Linux) or Cmd + T (Mac) to quickly open the ROI Manager. If the shortcut does not automatically add the ROI then select "Add [t]".
- To view the coordinates, select "Properties" > "List Coordinates" and click "Ok".
In the provided code, the bounding box argument (bbox) is entered as (x min, y min, x max, y max).

The results for one region of interest from the nucleus segmentation are shown in Figure 3.
# Plot the nucleus segmentation
# bbox=(x min,y min,x max,y max)
# Define a single color cmap
cmap=ListedColormap(['grey'])
# Create Plot
plot_mask_and_save_image(title="Region of Interest 1",gdf=gdf,bbox=(12844,7700,13760,8664),cmap=cmap,img=img,output_name=dir_base+"image_mask.ROI1.tif")
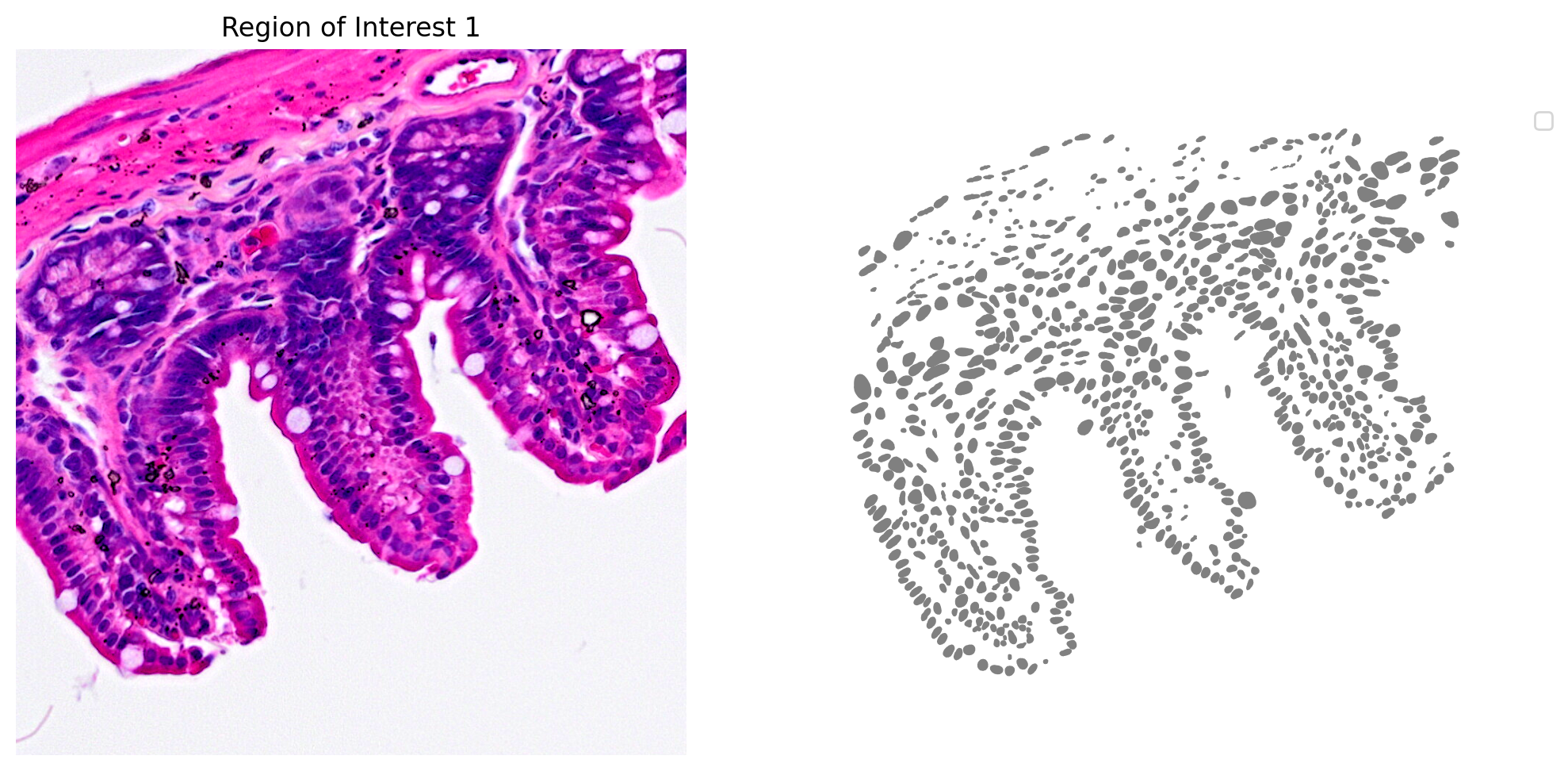
In the following code block, we load the 2x2 µm Visium HD gene expression data and tissue position information. A GeoDataframe is then created. Be sure that the expression data and tissue position files are in the same directory as the high-resolution H&E microscope image.
# Load Visium HD data
raw_h5_file = dir_base+'filtered_feature_bc_matrix.h5'
adata = sc.read_10x_h5(raw_h5_file)
# Load the Spatial Coordinates
tissue_position_file = dir_base+'tissue_positions.parquet'
df_tissue_positions=pd.read_parquet(tissue_position_file)
#Set the index of the dataframe to the barcodes
df_tissue_positions = df_tissue_positions.set_index('barcode')
# Create an index in the dataframe to check joins
df_tissue_positions['index']=df_tissue_positions.index
# Adding the tissue positions to the meta data
adata.obs = pd.merge(adata.obs, df_tissue_positions, left_index=True, right_index=True)
# Create a GeoDataFrame from the DataFrame of coordinates
geometry = [Point(xy) for xy in zip(df_tissue_positions['pxl_col_in_fullres'], df_tissue_positions['pxl_row_in_fullres'])]
gdf_coordinates = gpd.GeoDataFrame(df_tissue_positions, geometry=geometry)
We next check each barcode to determine if they are in a cell nucleus. There is a chance that two or more cell nuclei can overlap, so to remove barcode assignment ambiguity, we will later filter to retain only barcodes that are uniquely assigned.
# Perform a spatial join to check which coordinates are in a cell nucleus
result_spatial_join = gpd.sjoin(gdf_coordinates, gdf, how='left', predicate='within')
# Identify nuclei associated barcodes and find barcodes that are in more than one nucleus
result_spatial_join['is_within_polygon'] = ~result_spatial_join['index_right'].isna()
barcodes_in_overlaping_polygons = pd.unique(result_spatial_join[result_spatial_join.duplicated(subset=['index'])]['index'])
result_spatial_join['is_not_in_an_polygon_overlap'] = ~result_spatial_join['index'].isin(barcodes_in_overlaping_polygons)
# Remove barcodes in overlapping nuclei
barcodes_in_one_polygon = result_spatial_join[result_spatial_join['is_within_polygon'] & result_spatial_join['is_not_in_an_polygon_overlap']]
# The AnnData object is filtered to only contain the barcodes that are in non-overlapping polygon regions
filtered_obs_mask = adata.obs_names.isin(barcodes_in_one_polygon['index'])
filtered_adata = adata[filtered_obs_mask,:]
# Add the results of the point spatial join to the Anndata object
filtered_adata.obs = pd.merge(filtered_adata.obs, barcodes_in_one_polygon[['index','geometry','id','is_within_polygon','is_not_in_an_polygon_overlap']], left_index=True, right_index=True)
Next we perform a gene-wise count summation for the custom binned data. This step will take a few minutes to execute and can vary based on the number of nuclei in the image.
# Group the data by unique nucleous IDs
groupby_object = filtered_adata.obs.groupby(['id'], observed=True)
# Extract the gene expression counts from the AnnData object
counts = filtered_adata.X
# Obtain the number of unique nuclei and the number of genes in the expression data
N_groups = groupby_object.ngroups
N_genes = counts.shape[1]
# Initialize a sparse matrix to store the summed gene counts for each nucleus
summed_counts = sparse.lil_matrix((N_groups, N_genes))
# Lists to store the IDs of polygons and the current row index
polygon_id = []
row = 0
# Iterate over each unique polygon to calculate the sum of gene counts.
for polygons, idx_ in groupby_object.indices.items():
summed_counts[row] = counts[idx_].sum(0)
row += 1
polygon_id.append(polygons)
# Create and AnnData object from the summed count matrix
summed_counts = summed_counts.tocsr()
grouped_filtered_adata = anndata.AnnData(X=summed_counts,obs=pd.DataFrame(polygon_id,columns=['id'],index=polygon_id),var=filtered_adata.var)
%store grouped_filtered_adata
In this demonstration, we filter the results to remove very large nuclei, which could be improperly segmented nuclei aggregates or image artifacts, and remove nuclei with too few UMI counts to make cluster interpretation and visualization easier. This step is optional and performing it will likely depend on the sample.
# Store the area of each nucleus in the GeoDataframe
gdf['area'] = gdf['geometry'].area
# Calculate quality control metrics for the original AnnData object
sc.pp.calculate_qc_metrics(grouped_filtered_adata, inplace=True)
# Plot the nuclei area distribution before and after filtering
plot_nuclei_area(gdf=gdf,area_cut_off=500)

Based on the nuclei distribution we selected a value of 500 to filter the data.
Next we plot the total UMI distribution.
# Plot total UMI distribution
total_umi(grouped_filtered_adata, 100)

For this dataset, a total UMI cutoff of 100 was used. These values (nuclei area and UMI cutoff) may need adjustment for other datasets. Selecting appropriate cutoff values might require iteration based on the intepretation of the clustering results.
The following code block filters the data.
# Create a mask based on the 'id' column for values present in 'gdf' with 'area' less than 500
mask_area = grouped_filtered_adata.obs['id'].isin(gdf[gdf['area'] < 500].id)
# Create a mask based on the 'total_counts' column for values greater than 100
mask_count = grouped_filtered_adata.obs['total_counts'] > 100
# Apply both masks to the original AnnData to create a new filtered AnnData object
count_area_filtered_adata = grouped_filtered_adata[mask_area & mask_count, :]
# Calculate quality control metrics for the filtered AnnData object
sc.pp.calculate_qc_metrics(count_area_filtered_adata, inplace=True)
To assess the binning results, we examine gene expression and clustering. In the next block of code, the results undergo clustering. It is important to note that the resolution parameter used in Leiden clustering may need adjustment when working with different datasets.
# Normalize total counts for each cell in the AnnData object
sc.pp.normalize_total(count_area_filtered_adata, inplace=True)
# Logarithmize the values in the AnnData object after normalization
sc.pp.log1p(count_area_filtered_adata)
# Identify highly variable genes in the dataset using the Seurat method
sc.pp.highly_variable_genes(count_area_filtered_adata, flavor="seurat", n_top_genes=2000)
# Perform Principal Component Analysis (PCA) on the AnnData object
sc.pp.pca(count_area_filtered_adata)
# Build a neighborhood graph based on PCA components
sc.pp.neighbors(count_area_filtered_adata)
# Perform Leiden clustering on the neighborhood graph and store the results in 'clusters' column
# Adjust the resolution parameter as needed for different samples
sc.tl.leiden(count_area_filtered_adata, resolution=0.35, key_added="clusters")
When the clustering results are plotted, we see clusters that align with morphological features (Figure 6).
# Plot and save the clustering results
plot_clusters_and_save_image(title="Region of interest 1", gdf=gdf, img=img, adata=count_area_filtered_adata, bbox=(12844,7700,13760,8664), color_by_obs='clusters', output_name=dir_base+"image_clustering.ROI1.tiff")
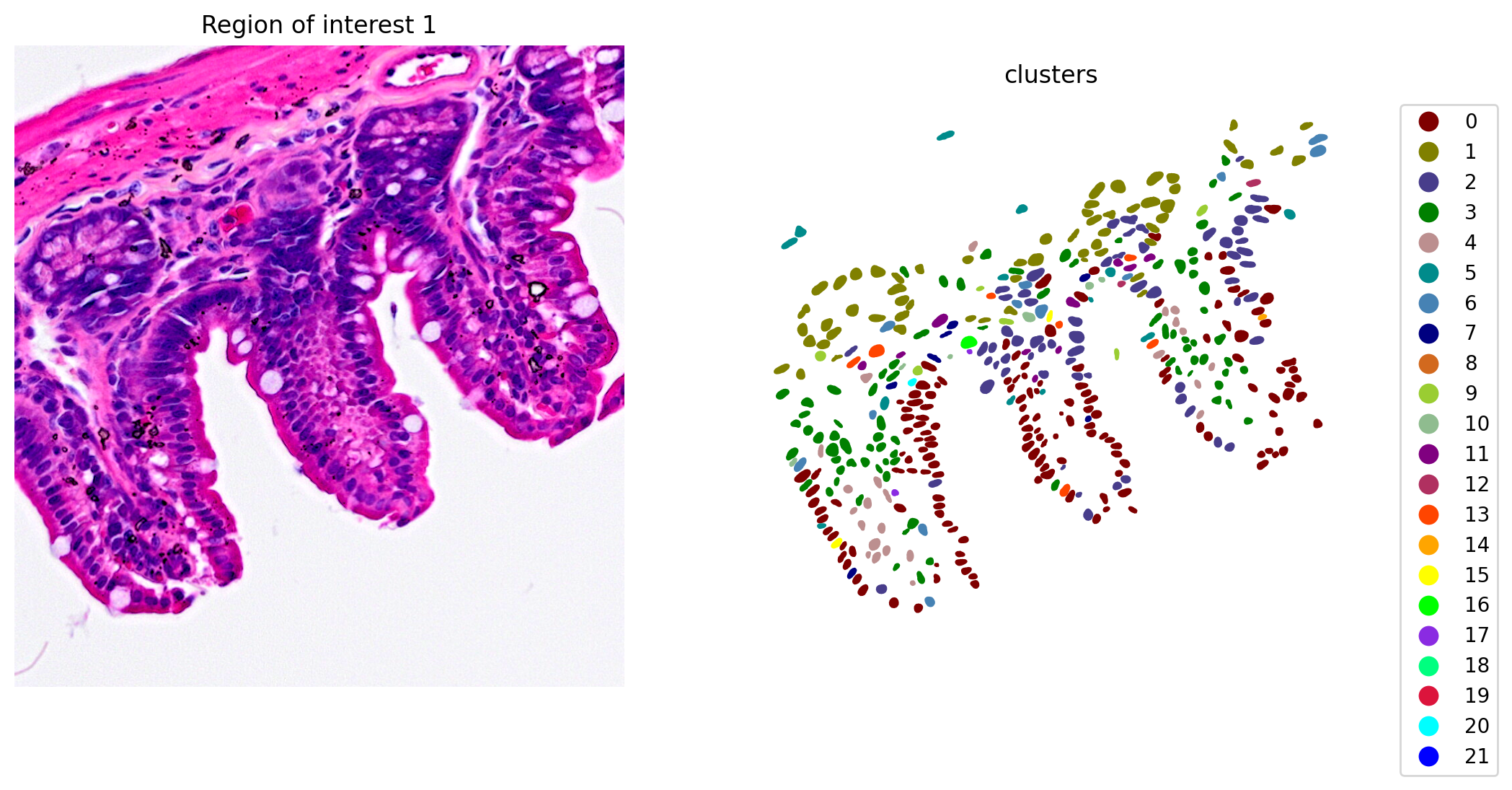
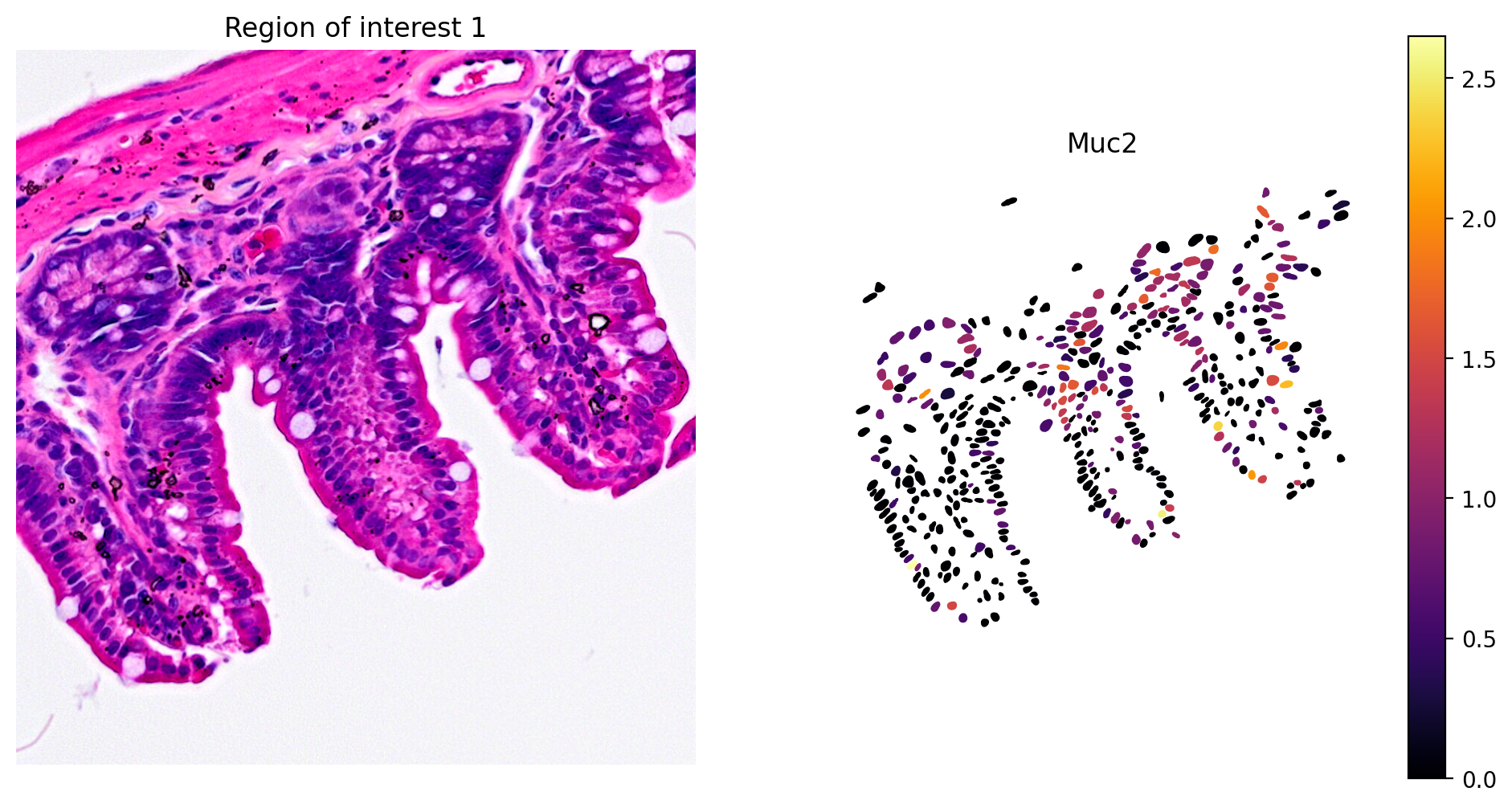
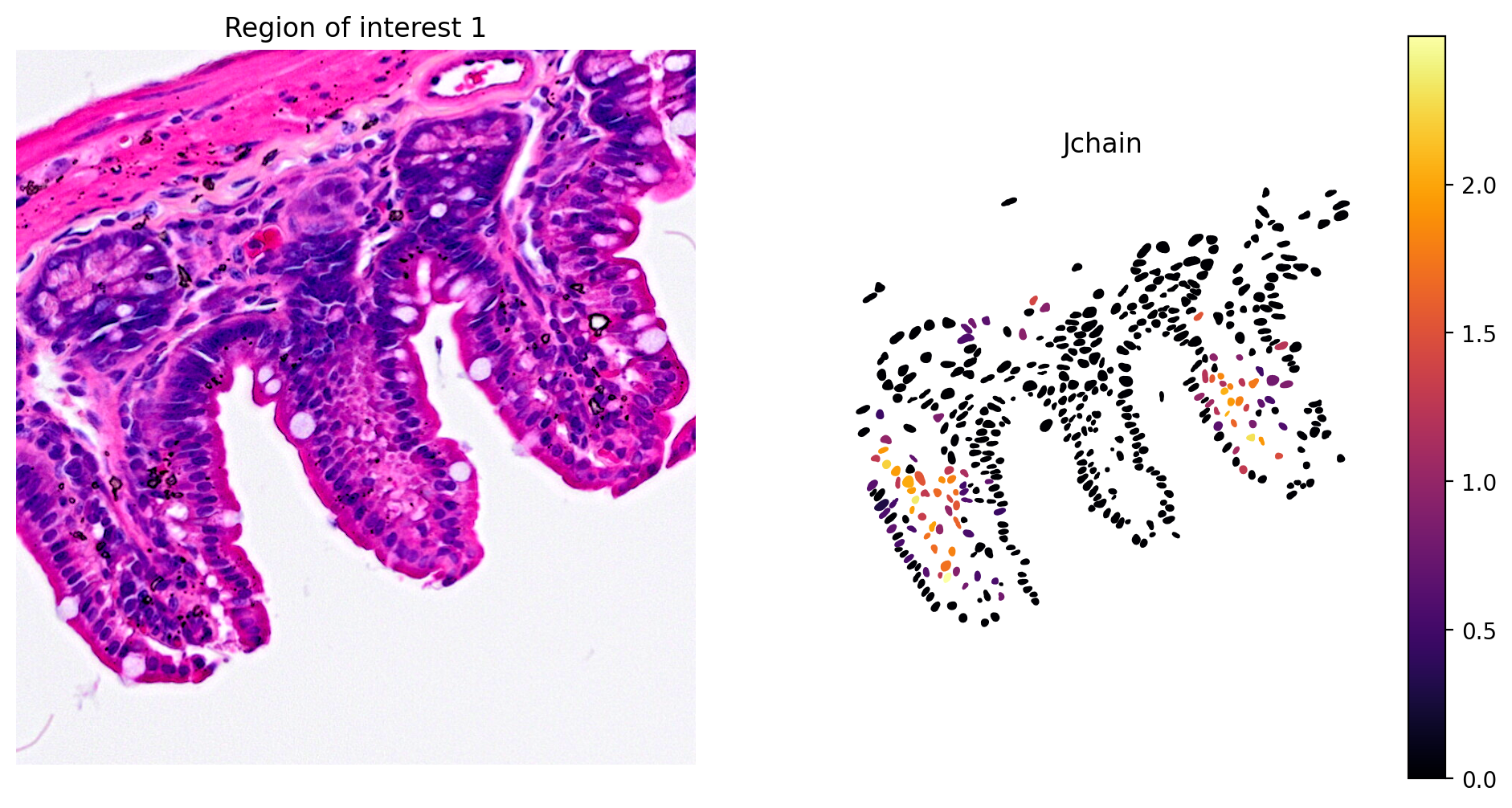
In addition, marker gene expression matches tissue morphology. For example, we see:
- Paneth cell expression of Lyz1 (Figure 7)
- Goblet cell expression of Muc2 (Figure 8)
- Enterocyte cell expression of Fabp2 (Figure 9)
- Plasma cell expression of Jchain (Figure 10)
# Plot Lyz1 gene expression
plot_gene_and_save_image(title="Region of interest 1", gdf=gdf, gene='Lyz1', img=img, adata=count_area_filtered_adata, bbox=(12844,7700,13760,8664),output_name=dir_base+"image_Lyz1.ROI1.tiff")

# Plot Muc2 gene expression
plot_gene_and_save_image(title="Region of interest 1", gdf=gdf, gene='Muc2', img=img, adata=count_area_filtered_adata, bbox=(12844,7700,13760,8664),output_name=dir_base+"image_Muc2.ROI1.tiff")
# Plot Fabp2 expression
plot_gene_and_save_image(title="Region of interest 1", gdf=gdf, gene='Fabp2', img=img, adata=count_area_filtered_adata, bbox=(12844,7700,13760,8664),output_name=dir_base+"image_Fabp2.ROI1.tiff")

# Plot Jchain expression
plot_gene_and_save_image(title="Region of interest 1", gdf=gdf, gene='Jchain', img=img, adata=count_area_filtered_adata, bbox=(12844,7700,13760,8664),output_name=dir_base+"image_Jchain.ROI1.tiff")
In this Analysis Guide we showed how to use the nuclei information from a H&E image to bin gene expression data. We validated the results by observing marker expression and clustering that matched tissue morphology. The approach will work best for images that have well defined large cell nuclei that are easily distinguishable from each other and the background. As we saw, there are a number of steps that will likely require parameter optimization for any new H&E image and Visium HD gene expression dataset. Key parameters to keep in mind are the probability threshold, the clustering resolution, and the total UMI and nuclei size filter cutoffs.
Beyond parameter optimization, there are some refinements to this approach which may improve results. In this example, we used StarDist's pre-trained H&E classifier model. It is beyond the scope of this Analysis Guide, but StarDist can use custom trained models. For additional detail please see StarDist's documentation. Furthermore, we only considered nuclei information. Expansion of the boundaries of each individual nucleus in the nuclei mask could improve results. Finally, we only considered StarDist in this Analysis Guide, other algorithmic approaches, such as Cellpose or image thresholding coupled with watershed segmentation, may perform better depending on the data and experimental goals.
We used the Python programming language to create the custom mask, but there are software options that create image masks, like Qupath and Fiji. In fact, both Fiji and Qupath implement StarDist's segmentation method as well as additional methods, which makes it easier to explore different segmentation approaches. Regardless of the approach as long as a morphologically relevant mask is created, Visium HD gene expression data can be custom binned using the approach described here.